
Bechdel Test Visualization
In my final project for CS 625: Data Visualization, I produced a static explanatory visualization to show the relationship between budget and genre with respect to Bechdel test. The chart shows that constantly over time, movies that fail the bechdel test have higher budgets than movies that pass, across all genres. I used the ggplot2 R library to create my visualization, and followed the visualization principles described in Munzner’s Visualization Analysis and Design.
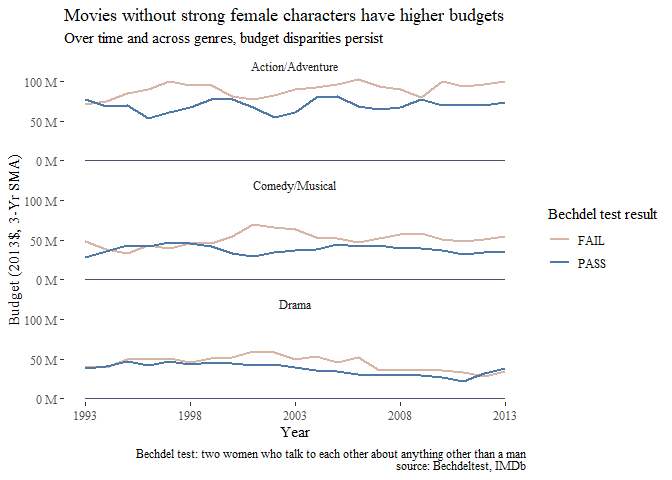
I chose to use the Five Thirty Eight data set on the Bechdel test for my CS 625 visualization project. The Bechdel test is used as a minimum standard for determining whether women are represented in a movie. In order for a movie to pass the test, there must be two women who talk to each other about anything other than a man. The Five Thirty Eight data set includes complete data for 1,615 movies and incomplete data for another 179 movies. The data includes the year and title of the movie, the IMDb ID, detailed information about why the movie passed or failed the bechdel test, and box office information. All of the data except for the box office information came from Bechdeltest.com. The box office information came from The-numbers.com.
For a secondary data set, I chose to use WikiData to obtain the gender of the screenwriters of the movies in the original data set. The original screenwriter gender data obtained from WikiData includes male, female, transgender male, transgender female, and non-binary for each screenwriter associated with a movie, as well as some movies not having any screenwriter gender information. The 5 genders were converted into 3 gender fields to represent one cumulative gender of all screenwriters associated with a movie. The final choices for the screen writer gender field are all_male, all_female, and other (as well as unknown for when no screenwriter information was found). Other includes a mix of genders as well as non-binary genders. I used SPARQL and the pandas Python library to collect and clean this data set.
For a secondary data set, I chose to use IMDb to obtain the genres and ratings of the movies in the original data set. The comma separated genre field obtained directly from the IMDb data set includes 21 genres. The 21 genres were converted into 3 genre clusters. The final choices for the genre field are Action/Adventure, Drama, and Comedy/Musical. I used Perl and the pandas Python library to clean this data set.